A Point Set Generation Network for3D Object Reconstruction from a Single Image 논문 요약
기존의 연구는 volumemetric이나 이미지들에 대해서 규칙적인 표현에 의존을 하고있습니다.
그러나 이 논문은 자연상태에서는 3D shape이 규칙적이지 않고 많은 문제를 겪는다고 이야기를 하고 있습니다.
(자연 상태에서의 물체의 2D 메시와 point clouds는 규칙적인 구조를 가지고 있지않습니다.)
그리고 이 논문은 단일 input에서 3D 재구성 문제를 해결합니다.

하나의 input 사진으로 3d reconstructed를 성공했음을 보여줍니다.
거기다가 사진도 현재 도심속에서 흔히 볼 수 있는 상태죠
기존의 연구에서는 3d데이터의 볼륨이나 이미지컬렉션에서 깊은 신경망을 사용해야하는데 이것은 sample resolution(셈플의 해상도) 와 net efficiency(효율성) 사이에서 trade_offs의 문제를 야기시킵니다.
3d geometry를 위한 generative network를 point cloud의 표현으로 기초했습니다.
하지만 point cloud는 CAD와 비교해서 단순한 mesh를 가지고있으면 효율적이지 않을 수 도 있습니다.
그러나 point cloud는 간단해서 학습하기가 쉽고 다양한 primitives와 균형적인 연결패턴을 encode할 필요가없습니다.
게다가 point cloud는 기하학적 변형에 대해서 간단한 조작이 가능합니다.
일반적인 L2 유형의 Loss와는 달리 loss를 효율적으로 해결하기위해 Earth Mover's distance(EMD)라는 방식을 도입합니다. 그리고 EMD를 이용하면 다른방식으로 end-to-end 학습을 보장한다고 합니다.
대부분의 경우 multi-view에 초점을 둔 SFM모델과 SLAM모델을 사용하는데 single-view 이미지로 3D재구조화를 할 수 있습니다.
대부분의 물체에 N=1024를 입력하면 향상됨을 보았다고합니다.
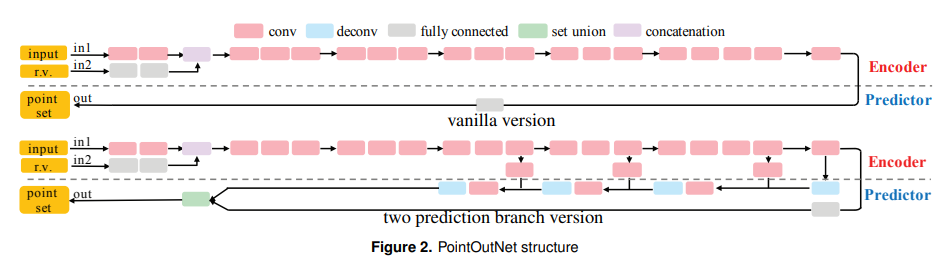
단지 포면의 point를 이용해서 encoding을해 높은 효율의 point set을 보였다고합니다.
이 논문은 새로운 아키텍쳐를 제안하는데 point set generator 아키텍쳐를 제안합니다.
point set을 보면 prediction과 groundtruth사이의 거리를 측정하는 방법이 불명확합니다 그래서 두가지의 거리 metrics를 제안하는데 바로 Chamfer 거리와 Earth Mover's 거리 입니다.
이 네트워크는 encoder stage와 predictor stage를 가집니다.
encoder map은 이미지 한쌍과 랜덤 벡터가 embedding space에 들어옵니다.
그러면 predictor ouput은 N x 3의 matrix를 가지고 각행에 한점의 좌표가 들어와있습니다.
encoder는 convolution과 ReLU층으로 이루어져있고 랜덤벡터 r은 이미지의 예측을 방해하는 인자입니다.
predictors는 fully connected network를 통해 N개의 점의 좌표를 발생시킵니다.
이런 과정을 통해서 학습이 잘되도록 한다고합니다.
이 두개의 평핸한 branch는 하나는 fully-connected(fc) branch고 또다른하나는 deconv branch이다.
fc branch는 N point를 예측하고 deconv branch는 3채널의 H x W 이미지를 예측한다.
그리고 이것을 하나의 전체 point set으로 merge해줍니다.
그래서 이 두개의 skip link는 정보의 흐름을 가속화해주는 encoder와 predictor을 추가해줍니다.
이모델의 lose function은 EMD 뿐만아니라 Chamfer distance(CD)도 사용을하는데
CD알고리즘은 이웃한 값을 찾고 거리를 제곱합니다. 그리고 각각의 point들은 independent라고 합니다.
EMD 알고리즘은 optimization 문제를 해결해준다고합니다.(근데 계산량이 많다고합니다)

input 이미지를 가져오면 이런식으로 특징을 추출을한다고 합니다.

3D-R2N2보다 구조를 더 잘 보존하는것을 알 수 있습니다.
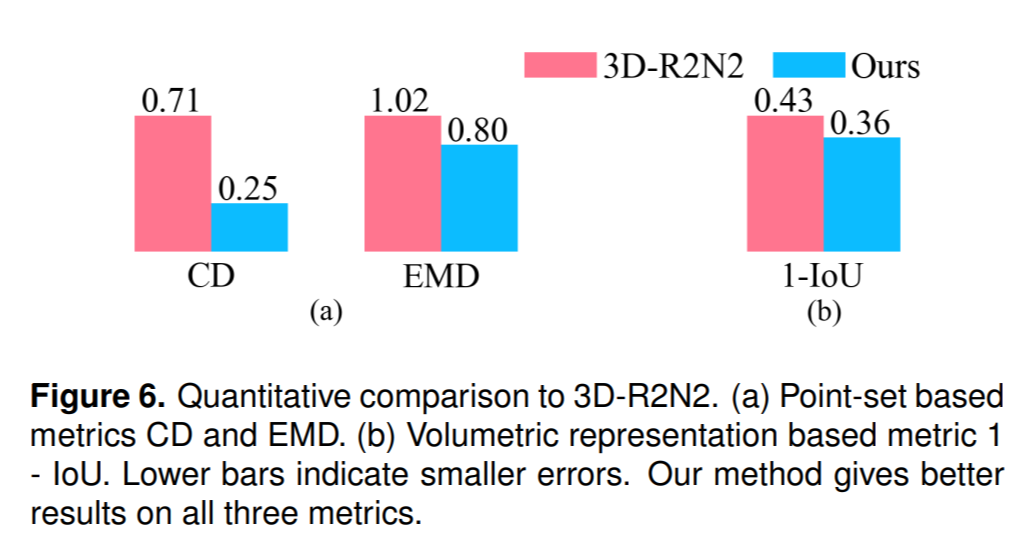
3D-R2N2보다 모든 loss fuction에서 더 작은 loss를 기록했다는것을 실험으로 보여줍니다

이 네트워크는 모델의 놓친부분을 성공적으로 추측합니다. 그리고 대칭성을 활용한다고합니다.
이러한 flexible한 표현들은 general한 모양과 기하적인 표현들을 이용한다고 합니다.
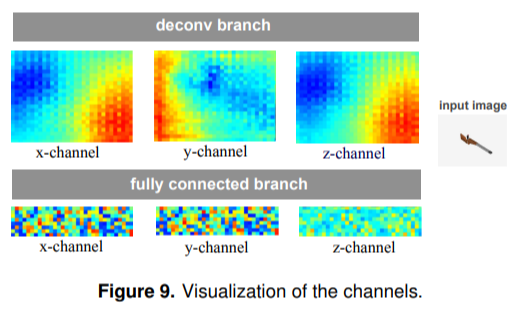
학습된 이미지들의 features를 시각화를 한 부분입니다.
결론 : The fully connected branch is more flexible but the independent control of each point consumes more network capacit