Abstract
지도학습은 learning할때 매우 효과적인것을 보여준다.
그러나 대부분 공간이나 temporal을 가지고있는 이미지나 오디오 텍스트같은 데이터augmentation이 가능한 데이터들이 대부분 좋은데 tabular(정형데이터)는 이러한 이점을 가지고있지않다.(효과적인 데이터 augmentaiton이 가능하지않아서)
이 논문에서는 Subsetting features of Tabular data를 제안한다. SubTap은 tabluar 데이터로부터 배우는 task를 muti-view representation learning문제로 넣는다. input features를 multiple subset(부분집합)으로 나눈다.
이 저자들은 autoencoder보다 featuer의 subset으로부터의 재구조화한 데이터가 잘사로잡는다 하위의 잠재된 표현을
Introduction
audio와 이미지는 주로 spatial, semantic, temporal 구조의 장점이있어 data augmentation이 가능하지만 구조가 부족하다면 데이터가 덜 효과적일수가있다 많은 분야 healthcare, advertise, finance, law같은 분야에서의 tabular데이터는 비슷한방식의 data augmentation이 어렵고 이러한 augmentation은 tabular데이터에 맞지않다. 이것은 이 도메인에서 지도학습이 낮은학습을 보이는이유다.
tabular 데이터에서 가장흔한 접근방식은 noise를 통해 데이터를 corrupt시키는것이다.
autoencoder map은 충돌시킨다. 그리고 데이터의 예시를 남겨진 공간에 그리고 maps는 다시 uncorrupted data로 되돌린다.
이러한 과정을 통해서 이것은 배운다. input에서 노이즈의 표현이 공고해진다.
그러나 이것은 덜 효과적일수도있다. 모든 feature들이 공평하게 대우받기때문에 feature들이 동등하게 정보를 제공하기때문이다.그러나 교환된 uninformative feature는 손상된 목표의도안에서 결과가 되지못할지도모른다.
한연구에서 tabular data에서 pretext task를 소개함으로써 지도학습의 장점을 밝혔다.

i : subset으로 feature를 나눈다. - 배깅(sample을 여러번뽑아 모델에 넣고 그 모델들을 집계하는방식)과 비슷
ii : 부분집합된 feature들을 재구조화한다. 또한 결정한다. feature space를 그리고 이것들은 reconstruction loss를 계산하는데 이용된다.
iii)발생된 projection은 대조와 거리 loss를 사용하기위해 계산이됩니다.
E = Encoder
D = Decoder
G = Projection
그 classifier의 task는 손상된 feature의 위치를 예축한다. 그러나 이 framework는 여전히 데이터 노이즈에 의존한다.
게다가 training된 classifier의 불균형한 binary mask 고차원적인 데이터는 의미있는 표현을 학습하지 못할 수 있다.
이 연구에서는 우리는 표현을 배우는 문제를 바꾼다.
데이터를 single-view 에서 multiple view로 feature을 부분집합으로 나눔으로써 문제를 바꾼다.
확신한다. 이미지 안에서의 crop과 앙상블안에서의 feature배깅은 데이터의 다른 관점을 발생시킨다.
각각의 부분집합은 다른관점으로 고려 될 수 있다.
그것들의 feature들의 subset으로부터 재건축된 데이터는 인코더가 더 표현을 잘 배우도록 강요한다.
noise를 추가하는 방법을통해서 우리는 train한다.
SubTab은 다음을 수행할 수 있습니다: i) 표현의 집계를 사용하여 더 나은 표현을 구성합니다
하위 집합, 우리가 협업 추론이라고 부르는 과정 ii) 정보 영역을 발견합니다
특히 고차원에서 유용한 각 부분 집합의 예측 검정력을 측정하여 기능
data iii) 해당 기능을 무시하여 누락된 기능이 있는 경우 훈련 및 추론 수행
부분 집합 및 iv)는 입력 치수를 줄여 더 작은 모형을 사용하므로 과적합이 발생하기 쉽습니다.
2. Method
noise, rotation, cropping과 같은 augmentation 방법은 주로 이미지 domain에 사용이된다. 이것들 사이에서 cropping은 가장 효과적인 기술이다. 인사이트를 고무시키고 우리는 정형데이터의 subsetting features를 제안한다.
Fugure 1은 SubTap framework이다. 이논문의 목적은 h 는 latent이고 representation이다. z는 porjection이고 x는 subset의 재구조화된 부분이다. small한 부분들은 연관되어있다. subset들과 전체의 주요한 부분들을 features의 전체 set과 연관되어있다.
이 subtap framework에서 우리는 . tabular data를 multiple subset으로 나눈다
이웃한 subset들은 지역을 overlapping할 수 있다. subset차원의 퍼센테이지를 정의함으로써
각각의 subset들은 동일한 encoder에 공급한다. 그들의 충돌로 latent representation을 얻기위해서
한 공유된 deoder은 재건축에 사용된다. encoder에 공급한 subset으로 또한 full tabular data(모든 features들이 subset의 feature들로부터 재건축된)으로
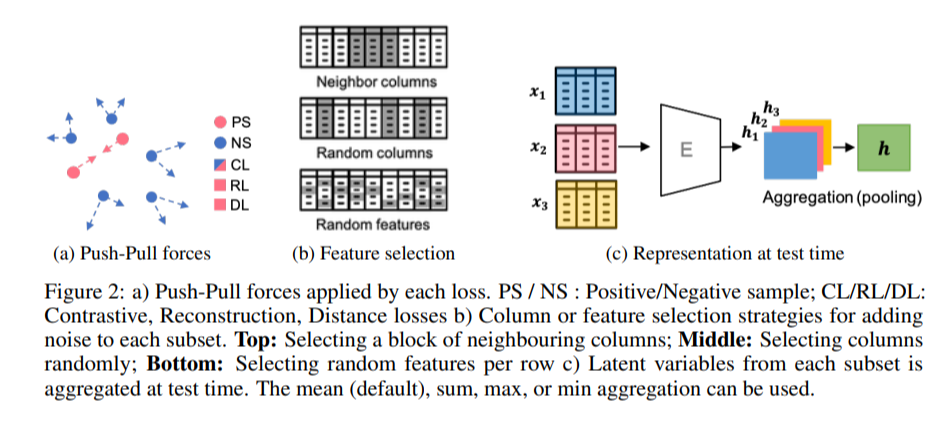
a) Push_Pull forces는 각각의 loss에 적용된다. PS/NS : Positive/ Negative sample
CL/RL/DL : 대비, 재구성, 거리 손실
b) column 과 feature selection 전략이다. 각각의 subset에 노이즈를 추가한Top : 이웃 columns middle : random columnbottom : random featuresc) 각각의 subset에 Latent된 variables들은
테스트시간에 집게되었다 - 평균(기본값), 합계, 최대값 또는 최소값을 사용할 수 있습니다.
우리는 후자의 case에 집중한다.
1.오토인코더는 identity를 학습할 수 없다(오토인코더의 단점중하나가 x를 넣었는데 x가 나옴으로써 새로운데이터를 만들지 못하는 문제가있다.)
2.bottleneck의 차원의 제약을 제거한다.
게다가 우리는 선택적으로 모든 subset의 조합을 사용하여 우리의 객체에 대조적인 손실을 추가할 수 있습니다
우리는 loss term을 더 추가할 수 있습니다. 거리 loss를 언급함으로써 loss fuction을 사용함으로써 subset에 투영된 projection의 쌍과 MSE의 거리를 줄이기위해서
세가지의 손실 term은 positive samples을 pulling을 적용한다. 반면에 negative loss는 push를 적용한다. 그림 2a에 표시된 positive와 negative samples을 보여줌으로써
데이터의 준비에서 dataset은 subset안으로 나눠진다. 이 과정은 비슷하다 앙상블에서 feature을 배깅시키는것과 비슷하다. 그들의 위치는 고정된다. 그래서 우리는 subset의 feature의 상대적인 순서를 바꾸지않는다. training하는 동안 표준 뉴럴 네트워크 아키텍쳐는 순열불변이 아니기 때문에이것은 보장한다. 같은 features들은 같은 뉴럴 네트워크의 input 유닛에 공급이된다.그러나 우리의 방법은 확장될 수 있다 변하지않는 순열로 다음단계로써
2.1 Strategies for adding noise
우리의 framework는 보완적인 다른 augmentation된 기술을 사용한다. tabular data setting에서그래서 우리는 실험했다 랜덤한 선택된 각각의 subset의 항목에 노이즈를 추가함으로써 세가지의 noise를 추가했다.i) 가우시안 노이즈를 추가 ii) swap-noise라고 언급된 같은 칼럼으로부터 또다른 랜덤한 sampled 값들과 함게 선택된 항목의 값들을 overwriting(덮어쓰는방법)iii) zeoring - out은 랜덤하게 항목들을 선택한다. zero-out noise라고 불린다.
게다가 우리는 세가지의 다른 전략들을 사용한다. feature에 노이즈를 추가하는것을 선택할때 Figure2b를 보면noise를 추가하기위해서 우리는 이항 mask를 만든다
마스크의 항목이 확률 p와 함께 1에 할당되는 경우,
그렇지 않으면 0이 된다.
3. Experiments
MNIST 데이터셋과 다양한 Tabular Dataset들, 다양한 지도학습모델과 autoencoder등을 실험했다.
3.3 Results
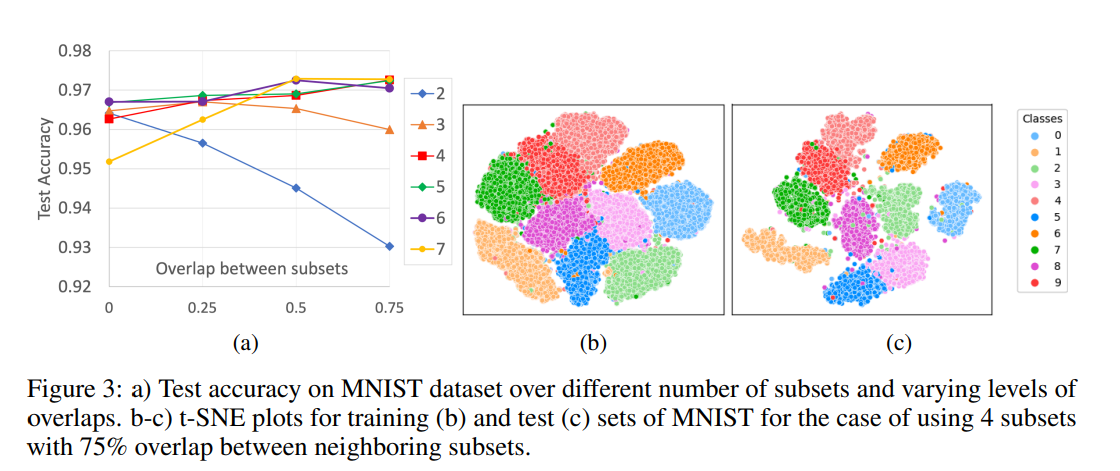
a) 다양한 하위 집합 수와 다양한 중첩 수준에 대한 MNIST 데이터 세트의 정확도를 테스트합니다.
b-c) train b와 test c의 t-SNE plot 이웃한 subset들의 75%를 overlap한 부분

a) 75% 오버랩한 네개의 subset들의 base 모델을 train시킨 후 subset들의 다른 개수를 사용한 결과를 테스트한부분
우리가 subset들을 증가함에따라 그 성능을 향상시켰다.
b) 비교하면서 우리의 모델을 CNN-based의 SOTA 모델들을 비교한것이다.
i) 입력 데이터의 노이즈 없음,
iii) 입력 데이터의 노이즈와 투영 쌍{zi, zj..}에 대해 계산된 거리 손실도 추가
SubTap에서 우리는 input의 노이즈없이 우리의 base model을 여러번 훈련시켰다.
각각의 train동안 우리는 사용했다 다른 레벨의 오버랩된 subset들의 개수를 이웃한 subsets들 사이에서
그러나 subset들이 증가하면서 그 성능은 점진적으로 증가했다 이웃한 subset들 사이에서 공유된 featuer의 개수를 늘림으로써
우리의 결과는 보여주었다 k = 4의 75%의 오버랩과 k = 7의 50% 오버랩들이 MNIST dataset에서 가장 좋은결과를 보여주었다.
Figure 3은 K=4의 75% 오버랩된 Test Sets들이 높은 퀄리티의 Clustering을 보여주었다고 보여주었다.
noise 없이 우리의 base model은 다른 지도학습 모델들과 autoencoder baseline을 능가했다
우리는 실험했다 모든 지도학습 모델에 세개의 노이즈를 주고 그리고 입력에 스왑 노이즈를 추가하면 성능이 향상된다는 것을 관찰했다.
subtap에서거리 손실을 추가하고 마지막 레이어의 치수를 128에서 512로 늘리면 성능을 향상시킬 수 있었다.


결과는 SubTap이 테스트시 누락된 features들을 잘 수용할수있으며 여전히 좋은 성능을 수행하는것을 나타낸다.
subset의 수행은 아마도 missing features가 존재할때 불확실하게 다뤄지는 방식을 더 좋게 바꿀지도모른다.
게다가 우리는 실험을 하면서 i) 정보가없는 subset은 추가할수가 있다 전반적인 의미를 그리고 그 수행이 위험하지않ㄴ다.
ii) 학습되지않은 모델은 더욱더 잠재된 정보를 가지고있는 subset분석에 사용되어질 수 있다
ii) 일단 모델이 subset 대해 훈련되면, 개별 subset들의 성능은 다른 subset과 함께 훈련되는지 여부를 바꾸지 않는다.예를 들어, 그림 5b의 모든 모델에서 하위 집합 3, 4, 5의 성능을 비교한다.
iv) 우리의 프레임워크 뒤에 있는 일반적인 아이디어는 훈련되지 않은 모델에서도 작동한다.
v) 우리는 단순히 데이터를 누락된 하위 집합으로 무시할 수 있기 때문에 프레임워크에서 데이터를 귀속시킬 필요가 없을 수 있다. 이는 귀속이 일반적으로 데이터와 결과를 왜곡하기 때문에 좋다.

e, Yoon et al. [46]는 classifier가 부착된 노이즈 제거 autoencoder를 사용했다.
랜덤이진마스크가 생성되어 정형데이터의 항목의 일부를 마스킹하고 덮어쓴다. 그리고 손상된 데이터는 encoder에 입력이된다.
autoencoder에서 de-noise시키는것과 비슷한 디코더가 재구축된 손상되지않은 input데이터를 사용하는동안 그 classifier은 예측하기위해서 mask가 사용이된다.
첫째, 이 접근 방식은 모델이 쉽게 과대 매개 변수화되고 데이터에 과적합되기 쉽기 때문에 매우 고차원적이고 작고 노이즈가 많은 데이터 세트에서 잘 작동하지 않을 수 있다.
둘째 이 설정에서 분류기를 훈련하는 것은 불균형 이진 데이터 세트에서 모델을 훈련할 때 관찰되는 문제와 유사하게 매우 높은 차원, 희소 및 불균형 이진 마스크를 예측해야 하기 때문에 어려울 수 있다.
결론 : 많은 복잡한 계산이 필요할 경우도 생기고 testing time이 선형적이지만 정형데이터의 고차원적인 의미들을 동시에 가져올수있다.
댓글