Abstract
이논문은 VIT에서 새로운 question이 있었다고합니다. 거기다가 더 나아가서 self-supervised를 VIT에 적용시키고싶었다고합니다.
self-supervised VIT의 feature들은 이미지의 segmantic segmentation의 명확한 정보를 포함합니다. 그러나 VIT에서만큼 명백하게 특징들이 드러나지는 않습니다.
그리고 학습된 feature들에 대해 k-NN classifier로 성능을 측정해보았는데 imagenet 데이터에 대하여 top-1 acc가 78.3%에 도달하였다고 합니다.
그리고 이 저자는 momentum encoder와 multi-crop training과 Vit의 small patch들을 중요하게 생각했다고합니다.
그리고 간단한 self-surpervised method인 DINO를 발견했다고 합니다.
이저자는 DINO와 ViT를 이용해 80.1%의 성능을 이끌어 냈다고합니다.
Introduction
transformer는 convolution neural networks(convnets)를 대체할 수 있다고합니다.
VIT는 convnet을 대체할수있지만 명백한 장점은 아직 없다고합니다. 왜냐하면 vit는 많은 계산량을 요구하고 많은 데이터를 요구합니다.
이 저자들은 self-supervised로 pretraning된 Transforemr NLP에서 동기부여를 받았다고합니다.
그래서 Vision Transforemr와 self-supervised를 같이 적용하고싶어하는거같습니다.

self-supervised ViT 의 특징은 위 그림처럼 장면 layout과 object boundaries도 보여줄 수 있다고 합니다.
이 정보는 마지막의 self-attention의 마지막블록에서 access한다고 합니다.
self-supervised ViT의 k-NN 알고리즘에서 가장 잘 수행한다고합니다.(단 fintuning과 linear classifier와 data augmentation이없는 환경에서 가장 잘 수행한다고합니다.)
이논문은 DINO를 소개합니다.
DINO는 knowledge distillation의 아이디어롤 가져와서 self-supvervised로 teacher network의 otput을 예측 훈련시키고 cross entropy loss를 사용하여 momentum encoder를 사용합니다. 얼한 방법은 teacher model output의 충돌을 피해준다고합니다.
그리고 DINO와 VIT를 결합시켜 Self-supervised를 시도한 결과 80.1%의 성능을 얻었다고합니다.

DINO는 single이미지에서 x1, x2의 veiw를 생성한다고합니다.(multi-crop을 사용한 view 입니다.)
그리고 두개의 다른 random tranformation input 이미지는 student와 teacher network의 모델을 통과시킵니다.
이 두개의 netowrk는 같은 구조의 다른 파라미타들을 가지고 있습니다.
network output인 k차원의 feature는 softmax 함수로 normalized합니다. 그리고 비슷하게 cross-entropy loss를 사용한다고 합니다.
stop-gradient를 적용시켜서 teacher network의 gradient를 student network를 통해 propagate했다고합니다.
teacher network의 parameter는 student parameter의 평균으로 update가 된다고합니다.
Relate work
self-supervised learning은 classification에서도 집중을 합니다.
이논문은 classifying 대신 noise constrastive estimator (NCE)를 제안합니다.
하지만 이 접근법은 features를 비교하는뎅 많은 이미지들이 필요하고 큰 사이즈의 배치사이즈, 많은 memory bank들이 필요하다고합니다.
그리고 이논문은 BYOL을 소개합니다. 그리고 여기의 features들은 momentum encoder로 매칭하면서 훈련을 시켰다고합니다.
이논문은 self-supervised learning과 knowledge distillation을 결합했습니다.
Self-training and knowledge distillation
self-traning은 라벨링이 되어있지않은 instance를 propagation을 시켜 features의 퀄리티를 향상시켜줍니다.
0, 1인 hard label이 아닌 0.2, 0.7, 0.5인 soft label을 사용하는것은 knowledge distillation으로 불립니다.
그리고 knowledge distillation은 large network의 압축된 model의 output을 를 흉내내서 small network를 학습시킵니다.
이전의 연구는 self-supervised learning과 knowledge distilation을 결합시켰다고합니다.
그러나 이러한 연구는 pre-trained된 teacher network에 의존합니다. 반면에 우리의 teacher network는 다이다믹 하다고합니다.
이러한 방식으로 knowledge distilation은 post-processing에서 seelf-supervised pre-training을 하는게 아니라 직접 self-supervised objective가 된다고합니다.
Approach
3.1SSL with knowledge Distillation
이논문은 DINO를 사용했다고 합니다.
그러나 DINO는 knowledge distilation과 비슷합니다.
knowlodge distillation의 관점에서 DINO를 제시합니다.

DINO의 pseudo-code입니다.

Knowledge distillation는 student network를 학습할 때 출력을 주어진 teacher network와 일치시키는 학습 패러다임입니다.
이미지 가 주어졌을 때 두 신경망 모두 차원의 확률 분포 와 를 출력합니다.
확률 분포 는 네트워크 의 출력을 softmax function으로 정규화하여 얻습니다.
함수식입니다.

0와 는 temperature parameter이며 출력 분포의 뾰족한 정도를 조절합니다.
teacher network 가 주어졌을 때 student network의 파라미터 에 대한 cross-entropy loss를 최소화하여 두 신경망의 출력 분포를 일치시킵니다.
함수식입니다.
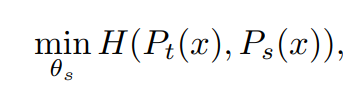
H(a,b) = -alogb 라고합니다.
다음은 어떻게 self-supervised learning에 적용하였는지에 대한 디테일한 부분입니다.
먼저, 저자들은 multi-crop strategy로 이미지의 다양한 distorted view나 crop을 얻습니다.
보다 정확하게는 주어진 이미지에서 서로 다른 view의 set 를 생성합니다. 이 set은 두 global view 와 작은 해상도에서의 몇몇 local view를 포함합니다.
모든 crop 이미지가 student를 통과할 수 있지만 teacher는 global view만 통과할 수 있다고합니다.그리고 이를 통해 local-to-global 대응을 장려합니다. 따라서 loss를 최소화합니다.

이 loss는 일반적이고 2개의 view뿐만 아니라 여러 개의 view에 대하여 사용할 수 있습니다.
저자들은 multi-crop 표준 설정대로 원본 이미지의 넓은 영역을 포함하는 22 해상도의 global view 2개와 원본 이미지의 좁은 영역을 포함하는 96 해상도의 local view 여러개를 사용하는데 이게 DINO의 기본 설정입니다.
두 신경망 모두 같은 아키텍처 를 사용하고 서로 다른 파라미터 와 를 가집니다. 는 위 loss 식을 SGD로 최소화하여 학습을합니다.
Teacher network.
knowledge distillation과 다르게 사전의 teacher network gt를 가지지않아서 teacher network를 student network의 이전 iteration으로 구축합니다.
저자들은 teacher network의 다른 업데이트 규칙을 실험했으며, teacher network의 epoch의 작업을 freezing하는것이 놀랍게도 좋았으며 반면에 student network의 가중치를 복사하는것은 teacher network가 수렴하는것을 실패했다고합니다.
exponential moving average(EMA)를 student weight에 사용하는 momentum encoder가 특히 잘 적합했다고합니다.
업데이트 규칙은 θt ← λθt + (1 − λ)θs이며 학습 중에 는 0.996에서 1로 증가하는 cosine schedule을 따릅니다.
원래 momentum encoder가 constrastive learning의 queue에서 소개되었습니다. 그러나 DINO에서는 queue와 constrastive loss를 사용하지않고 mean teacher의 역할로 self-training에 사용된다고합니다.
학습중에는 teacher의 성능이 student성능보다 더 좋으며 teacher가 target feature들을 고품질로 제공하여 student의 학습을 guide한다고합니다. 이러한 다이나믹함은 이전의 연구에서는 찾을 수 없었다고합니다.
Network architecture.
neural network g는 backbone으로 Vit or ResNet으로 구성이됩니다.
() Projection head는 layer 3개의 MLP, 정규화, 가중치가 정규화된 FC layer로 구성됩니다..
그리고 이것은 SwAV와 비슷하게 디자인됩니다.
이저자들은 다른 projection heads를 테스트했고 DINO에서 가장 성능이 좋음을 발견했다고합니다.
흥모롭게도 이저자들은 가장 표준인 convnet에 집중을 했고 ViT 아키텍처는 기본적으로 batch 정규화(BN)를 사용하지 않았음을 발견했습니다.
그러므로 VIT에서 DINO를 사용할때 projection head에서 BN을 사용하지않았습니다.
Avoiding collapse.
self-supervised method는 contrastive loss, clustering constraints, predictor, batch normalization 등등 collapse를 피하기위한 방법이 다양합니다.
DINO는 여러 정규화로 안정될 수 있지만 momentum teacher의 sharpening 과 centering을 이용하여 collapse를 피할 수 있다고합니다.
Appendix의연구에 따르면 centering은 한차원이 지배하는것을 막지만 uniform 분포에서 collapse을 야기합니다.
하지만 sharpening은 collapse을 방지해줍니다.
이 두 연산을 모두 적절히 사용해 momentum teacher의 collapse을 피해하기에 충분하도록 이 두 연산의 균형을 맞춰준다고 합니다.
collapse를 피하기위한 방법(centering)을 사용하면 batch에 덜 의존적이게되어 안정성은 낮아진다고 합니다.
centering은 1차 batch 통계에 만의존하고 teacher에 bias 항을 추가하는 것으로 해석할 수 있습니다.
gt(x)←gt(x)+c
center 는 EMA로 업데이트되며 batch size가 다르더라도 잘 적용된다고합니다.(Appendix에서 보여준다고합니다.)

여기서 0은 rate parameter이고 는 batch size이다. Sharpening은 teacher softmax normalization의 를 낮은 값으로 두는 것으로 할 수 있습니다.
3.2. Implementation and evaluation protocols
Vision Transformer

이논문은 다른network도 사용했다고합니다.
VIT 아키텍쳐는 겹치지않는 grid한 연속적인 N x N의 image 패치들을 입력으로 넣습니다.
이 논문에서는 N을 보통 N = 16 or N = 8로 넣었다고합니다.
이 패치들은 linear layer을 통해서 embedding을 형성합니다.
이논문의 저자들은 추가학습이 가능한 sequence에 들어가는 token을 추가했다고합니다.
이토큰의 역할은 전체 sequence의 정보를 집계하고 projection head h를 output에 붙여준다고합니다.
저자들은 이 token을 class token [CLS]라고 부릅니다.
패치 token과 CLS는 Transformer network에 "pre-norm" layer normalization을하고 입력된다고합니다.
transformer는 self-attention와 feed-forward layer의 sequence이며 skip connection을 병렬화됩니다.
self-attention layer는 token의 attention 매커니즘의 표현을 update합니다.
Evaluation protocols
Self-supervised learning을 평가하는 표준 프로토콜은 고정된 feature들을 linear classifer로 학습시키거나 feature을 downstream task에서 finetune합니다.
Linear evaluation을 위해서 random resize crop과 horizontal flips augmentation을 학습에 사용하고 central crop에 대한 accuracy를 측정합니다.
Finetuning evaluation을 위해서 사전 학습된 가중치로 신경망을 초기화하고 학습 단계에서 적응킵니다.
그러나 두가지방법의 evaluation은 hyperparameter에 민감하므로 learning rate를 바꾸면 실행할 때마다 정확도가 크게 변하는 것을 발견했다고합니다.
이 저자들은 feature들의 quality를 간단한 가중치 k-NN classifer로 측정했습니다.
pretrain model을 계산하기 위해서 고정시키고 downstream task의 training data의 features를 저장합니다.
그런 다음 k-NN classifer는 label에 투표하는 k개의 이미지의 features와 일치시킵니다.
저자들은 K = 20으로 두는 것이 전체적으로 성능이 제일 좋았다고 합니다.
이 evaluation protocol은 은 추가 hyperparameter tuning이나 data augmentation이 필요 없으며 down stream dataset에 대하여 1번만 실행하면 되기 때문에 feautre evaluation을 굉장히 간단하게 만든다고합니다.
4.1. Comparing with SSL frameworks on ImageNet
이 저자들은 같은 아키텍쳐와 아키텍쳐를 across한 두개의 아키텍쳐를 비교했다고합니다.

same architectures와 across archieectures에서 DINO가 가장 성능이 좋았음을 볼 수 있었습니다.
여기 실험에서 DINO의 VIT은 8X8의 이미지 patch를 사용했다고합니다.

위 사진은 Image retrieval에 대한 성능을 비교한 표입니다.
image retrieval은 컴퓨터 비전 분야의 한 부분으로, 대규모 데이터베이스에서 관련성이 높은 이미지를 찾는 기술입니다.
ImageNet 이나 Google Landmarks v2 dataset에서 사전학습된 features의 retrieval 성능을 비교했습니다.
여기에서도 DINO의 성능이 높음을 볼 수 있습니다.

위 사진은 copy detection task에 대한 성능 비교표입니다.
INRIA Copydays 데이터셋의 “강한” 부분집합에 대해서 mean average precision (mAP)를 측정하였습니다.
Copy detection task은 blur, insertions, print and scan 등으로 왜곡된 이미지를 인식하는 task입니다.
Discovering the semantic layout of scenes
이 저자는 DINO가 Figure1에서 보여진것처럼 image의 segmentation에 대해서 self-attention map들의 정보를 포함할 수 있다고합니다.
Video instance segmentation
DINO는 비디오 instance의 segmentation venchmark에 대해서도 평가를 했습니다.

video object segmentation을 평가한 표입니다.
은 mean region similarity이고 은 mean contour-based accuracy이다. 이미지 해상도는 480p로 평가를했습니다.

multiple head의 Attention maps 그립입니다. 다른 head들은 다른 color로 표현을 했다고합니다.

이그림은 supervised와 DINO의 segmentation 결과입니다.
Self-attention map에 임계값을 주어 mask를 얻어 시각화한 것입니다.
Probing the self-attention map
Fig4에서 이 저자들은 supervised ViT가 질적으로 양적으로 잘 집중하지 못한다고합니다.
저자들은 임계값 map을 60%를 유지해 ground truth와 segmentation mask 의 jaccard 유사도를 이용했다고합니다.
self-attention의 map들은 부드러워서 마스크를 생성해내기에는 최적화가 되지않았습니다.
그럼에도 DINO모델과 supervised 사이에서 Jaccard 유사성의 상당한 차이을 저자들은 발견을 했다고합니다.
잭카드 유사도(Jaccard similarity)는 두 집합 사이의 유사성을 측정하는 방법입니다.
Transfer learning on downstream tasks

이 저자들은 다른 downstraem task들도 pretrained된 DINO로 평가하고 supervised랑 비교했습니다.
Importance of the Different Components
이 저자들은Vit에서 학습시킨 self-supvervised에 다른 요소를 추가하면서 어떤영향을 끼치는지 실험했습니다.

Mom : momentum
Importance of the patch size

다양한 패치 크기에서 ViT-S 모델의 k-NN classification 성능을 비교한 것입니다.
모든모델은 300epoch를 돌렸다고합니다.
그리고 이 저자들은 patch 사이즈를 줄이면 서능이 증가함을 보았다고합니다.
6. Conclusion
이 저자들은 자체 지도 학습을 통한 표준 ViT 모델 사전 훈련의 잠재력을 보여주었고, 이 방법이 이러한 설정을 위해 특별히 설계된 최고의 컨볼루션 신경망과 비교할 수 있는 성능을 달성했다는 것을 확인했다고합니다.
또한 두 가지 특성이 향후 응용 프로그램에서 활용될 수 있다는 것도 알아보았습니다.
k-NN 분류에서 특징의 품질은 이미지 검색에 사용될 수 있는 잠재력이 있습니다.
또한, 특징에 포함된 장면 레이아웃 정보 역시 약한 지도 학습 이미지 세분화에 이점을 줄 수 있습니다.
'논문 > self-supervised' 카테고리의 다른 글
| Robust and Efficient Medical Imaging with Self-Supervision 논문정리 (0) | 2023.07.26 |
|---|

댓글