Abstract
knowledge distillation은 보통 큰 모델(teacher)을 흉내내기위해 small model(student)에서 훈련되었다고합니다.
이 아이디어는 output의 예측값을 soft label로 student 모델을 optimize 되는거에 의해서 teacher model으로부터 지식을 압축하기위해서 사용한다고합니다.
그러나 teacher모델이상당히 클때 이점이 없는데 이때 internal teacher 모델의 knowledge는 student로 옮겨집니다.
심지어 만약에 그 student모델이 가깝게 soft-label를 match한다면 그것의 internal 표현을 아마도 상당히 다르게 될것입니다. 이 internal mismatch는 teacher에서 student로 전달되어야할 일반화 능력을 손상시킵니다.
이 논문에서는 이 저자들은 large 모델의 BERT가 내부의 간소화된 버전으로 distill the internal resentation 하려고 한다고합니다.
위 저자들은 두가지의 방법으로 representation 과같은 distill와 다양한 distilation 계산 알고리즘을 제시합니다.
이 저자들은 GLUE의 benchmark의 데이터셋을 실험했고 또 지속적으로 보여주었다고 합니다. knolwedge distilation을 internal representation에 추가하는것은 soft-label distilation을 사용하는것보다 훨씬더 powerful한 방법이라고 얘기합니다.
Introduction
transfoermer-based 모델은 상당히 새로운 sota에서 큰 task를 처리하는 자연어처리 분야에서 이점이 있습니다.
BERT, GPT, GPT2, XLM, XLNet, RoBERT는 text classification, sentiment analysis, semantic role labeling 질문하고 답하는 분야를 이끕니다.
대부분의 모델은 백만개의 파라미타가 필요하고 많은 컴퓨팅 리소스가 필요하다고합니다.
여기서 가장 효과적은 기술은 teacher-student setting으로 되어있는 knowledge distilation(KD)이며 여기서 이미 최적화된 모델이 출력을 생성하고 간소화된 모델을 학습시킵니다.
one-hot-labels를 학습하는것과는 다르며 이 class들은 상호배타적이며 확률 분포를 사용하면서sample의 유사성에대해 더욱더 많은 정보를 제공합니다. 그리고 이것은 teacher-student distilation의 핵심이라고합니다.
그리고 student는 parameter를 적게 요구하는것과 동시에 teacher모델과 비슷한 퍼포먼스를 가집니다. 최근의 연구에서는 큰 model로부터 정보를 distilation하는것은 어려웠다고 말합니다.
2019년의 mirzadeh et al.의 연구에서는 teacher과 student의 차이가 크면 그 student 모델은 teacher모델을 근사하는데에 어려움을 겪는다고합니다.
이 저자들은 teacher로부터의 정보를 distill 하기위해서 teaching assistant(TA)모델을 사용합니다. 그리고 정보를 student로 distill하기위해 TA모델을 사용합니다.
그러나 이저자들은 논쟁합니다. large teacher에 의해서 capture된 추상화는 확률분포의 결과로 노출됩니다. 그리고 이것은 teacher의 internal knowledge를 student로 옮겨가기 어렵게 만듭니다.
이 논문에서 이 저자들은 KD에 internal representation을 적용시켰다고합니다.
이저자들의 접근법은 student가 효과적으로 그것의 언어 속성이 이전하는것에 의해 내부적으로 teacher처럼 행동하는것을 허락해준다고합니다.
이 저자들은 teacher의 다른 내부의 point를 distillation 하는것을 수행했습니다. 그리고 이것은 student가 배울수있고 larget model의 hidden layer에 있는 추상적인 표현들을 압축하는것을 해준다고합니다.
Methodology
이 저자들은 internel representation으로부터 distilling kinwledge의 과정을 구체화했다고합니다.
먼저 이 저자들은 standard KD framework를 묘사했다고합니다. 그리고 이것은 이 mothod에서 중요한 한 부분이라고합니다.
그러고나서 이 저자들은 transformer-based 모델에 internal knowledge를 distill 하기위해서 object function을 계산했다고합니다.
마지막으로 이 저자들은 다양한 알고리즘을 internal distillation 과정에서 계산했습니다.
Knowledge Distilation
KD프레임워크는 teacher - student setting을 사용하며 student는 실제라벨(가능한 경우)과 teacher에 의해 제공된 소프트라벨로부터 학습합니다.
소프트라벨에 속해있는 각각의 class와 관련된 확률 분포는 student가 sample에서 주어진 라벨의 유사성에 대해서 많은 정보를 배울수 있게 해줍니다.
KD 계산식은 soft 라벨과 hard 라벨이 고려됩니다.

θT는 teacher의 파라미터를 표현했습니다.
p(yi|xi, θT )는 soft label 입니다.
y^은 y p(yi|xi, θS)로 주어진 student prediction 입니다.
그리고 λ(람다)는 small scalar이며 hard-label의 loss의 weight를 down 시켜줍니다.
soft label은 자주 높은 entropy를 줍니다.
그 gradient의 경향은 hard label보다 더 작습니다.
그래서 λ 높은loss의 영향을 줄임으로써 항들 사이의 균형을 맞춥니다.
Match Internal Representations
student 모델을 tacher 모델처럼 행동하게 만들기위해서 student모델은 teacher모델의 output으로부터의 soft-label에 의해서 optimized됩니다.
게다가 그 student는 teacher의 추상적은 hidden부분을 teacher의 내부표현과 일치시키는 방식으로 습득합니다.
이저자들은 student를 student의 single layer에 있는 teacher로부터 multiple layer의 knolwedge를 압축해 어떻게 내부적으로 행동할지 가르치는것을 원했습니다.

internal representation으로부터의 knowledge distilation 입니다.
이 저자들은 internal layer를 보여주었다고합니다. teacher은 왼쪽 student에 있는 distilation 오른쪽입니다.
teacher layer가 student layer에 두배라는것을 보여줍니다.
색칠된 상자들은 student가 teacher의 내부표현을 배우는 layer를 나타냅니다.
student는 teacher layer에 걸쳐 언어적 행동을 유지하면서 두 layer을 하나로 합칩니다.
transformer layer을 매칭하고 이 저자들은 (1)모든 트랜스포커 헤드의 self attention 확률에 걸친 Kullback-Lebler (KL) 발산 손실과 (2)주어진 layer에 대해 [CLS]활성화 벡터간의 코사인 유사도 손실을 계산했다고합니다.
KL-divergence loss
A를 각토큰에 대해 행렬확률분포를 포함하는 self-attention matrix로 고려하고 A = softmax((d−0.5 a QKT ))에 의해sequence를 줍니다.
transformer layer에서 head를 주어주기 위해 이 저자들은 KL-divergene loss를 사용했다고합니다.
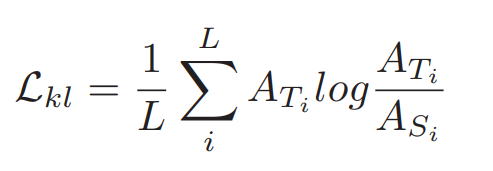
L은 sequence의 길이입니다.
Ati과 Asi는 student 모델과 teache모델의 self-attention matrix의 i번째 행을 묘사합니다.
Cosine similarity loss.
이 저자들은 cosine similarity의 제곱을 사용한다고합니다.
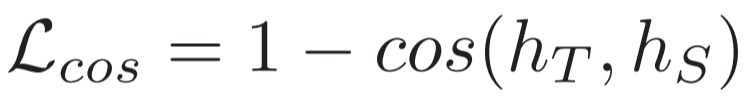
ht 와 hs는 student와 teacher의 [CLS] token 의 hidden 벡터 표현 입니다.

Stacked Internal Distillation(SID)알고리즘 입니다.
How to Distill the Internal Knowledge?
다른 layer는 taecher을 통해서 다른 언어적 개념을 사로잡는다.
모델이 하위 표현을 기반으로 구축되므로, 모든 내부 layer을 동시에 추출하는것 외에도, 이 저자들은 점진적으로 하향식 방식으로 내부 표현을 매칭하여 지식을 추출하는것도 고려합니다.
그리고 이 저자들은 두가지의 시나리오를 고려한다고 합니다.
1. Internal distillation of all layers
모든 epoch마다 student의 모든 layer는 teacher layer와 일치하도록 최적화됩니다.
Figure 1에서 1, 2, 3, 4가 원으로 표시된 부분에서 동시에 distilation이 일어납니다.
2. Progressive internal distillation (PID)
이 저자들은 하위layer에서 (입력에 가가운) knowledge를 증류하고 점진적으로 상위 layer로 이동하여 모델이 분류에 대한 지식추출에만 집중하도록 합니다.
한 layer는 동시에 최적화됩니다.
Figure 1에서 loss는 1 -> 2 -> 3 -> 4의 전환에 의해서 주어집니다.
3. Stacked internal distillation (SID)
저자들은 먼저 하위 layer에서 knowledge를 증류합니다. 그러나 독점적으로 한 layer에서 다른 layer로 이동하는것 대신에
이 저자들은 loss를 쌓아가며 상위 layer로 이동하는 동안 이전의 layer에서 생성된 loss를 보존합니다.
가장 상위의 layer에서 classification을 수행한다고합니다.
Figure 1에서 loss는 1 -> 1 + 2 -> 1+ 2 + 3 -> 4 로 수행한다고합니다.
이전 두 시나리오에서는 상위 layer로 이동하기위해서 student는 layer당 제한된 epoch에 도달하거나 코사인 손실 임계값에 도달하게 됩니다, 무엇이 먼저 일어나던간에(24 in Algorithm 1)
게다가, 이 두 시나리오는 모델이 최상위 계층에 도달할 때까지만이 아니라 항상 분류 손실과 결합될 수 있습니다.
Development and Evaluation Result

데이터셋을 다르게 주고 성능실험을 한 표입니다.
kl 과 cos 을 이용한 loss를 실험하였고
PID,SID를 이용해 knowledge distilation에도 적용한 성능을 비교했습니다.

선들을 따라 있는 점들은 BERT에서 사용된 layer의 수를 나타내고 x축은 Parameter수를 나타냅니다.
layer의 수를 줄이면 두 학습 모델 모두 성능이 줄어든다고 합니다. 그러나 Internal KD방법은 높은 성능을 유지하는데에 있어서 더욱 탄력적이라고 합니다.

Data셋의 사이즈가 커지면 커질수록 Standard KD와 Internal KD의 차이는 똑같다고합니다.
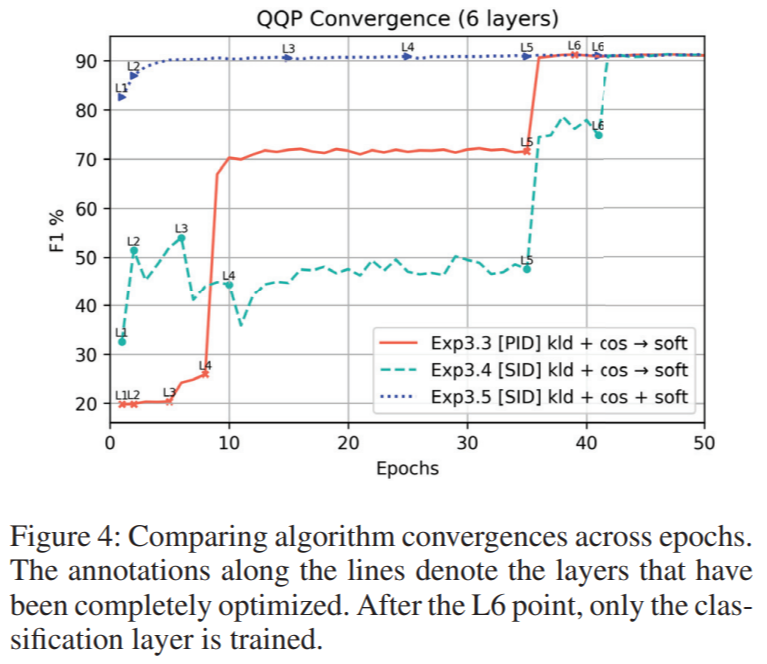
Exp3.3[PID] : progressive internal distilation
Exp3.4[SID] : stacked internal distilation
Exp3.5[SID] : 항상 soft label을 사용하는 stacked internal distilation
Exp3.3과 Exp3.4에서는 모든 tranformer lyer가 최적화 되었을때 40epoch까지 classification layer을 업데이트 해주지 않았다고합니다.
그럼에도 불구하고 internal distilationd자체만으로 student가 높은 포퍼먼스의 score에 도달할 수 있게 해주었다고 합니다.

student와 teacher 사이에 모든 일치하는 layer에서 KL-divergences loss는 Standard KD에서는 2.229 Internal KD에서는 0.085 였다고합니다.
Conclusions
이 저자들은 큰 모델을 효과적으로 작은 모델로 압축하면서도 원래 모델과 유사한 성능을 유지했다고 합니다.
표준 KD방법과 달리 student가 teacher의 출력 확률만 배우는 것이 아니라 이저자들은 teacher의 내부 표현도 공개함으로써 작은 모델들에게 가르친다고 합니다.
유사한 성능을 유지하는 것 외에도 이 방법은 teacher의 내부 동작을 student에게 효과적으로 압축합니다.
'논문 > knowledge distilation' 카테고리의 다른 글
| Deep Mutual Learning논문정리_2017 (0) | 2023.10.06 |
|---|---|
| Hierarchical Self-supervised Augmented Knowledge Distillation논문_2022 (1) | 2023.09.19 |


댓글