Abstract
저자들은 image에 따라서
1.시각적 개체의 크기 변동성이 큼
2.이미지의 픽셀 해상도가 단어에 비해 매우 높음
이러한 점들에서 기존의 vision Transformer에서 도전사항들이 있었다고합니다.
이러한 어려움을 다루기 위해서 이 저자들은 hierarchical Transformer의 representation을 Shifted sindows로 계산했다고합니다.
shifted windowing 방식은 비교적 효율적인 self-attention 계산을 위해 겹치지 않는 local window로 제한함으로써 더 큰 효율성을 가져오고 동시에 cross-window connection이 가능합니다.
이러한 hierarchcial 구조는 모델이 다양한 scale에서 더욱 유연하고 선형적인 계산 복잡성을 갖도록 해줍니다.
hierarchical한 디자인과 shifted window는 all-MLP 구조에서 이점을 줍니다.
Introduction

(a)Swin Transformer는 image patch들(회색으로 표시됨)을 더 깊은 계층에서 병합함으로써 계층적인 피처 맵을 구축하고, 각 local window(빨간색으로 표시됨) 내에서만 self-attention을 계산하기 때문에 입력 이미지 크기에 대해 선형적인 계산 복잡성을 가지고 이미지 classifiation과 recognition task 모두에 대한 일반적인 목적의 backbone)역할을 할 수 있습니다
( b) 반면에, 이전의 vision transformer는 단일한 저해상도의 피처 맵을 생성하며, global적으로 self-attention을 계산하기 때문에 입력 이미지 크기에 대해 quadratic한 계산 복잡성을 가지고 있습니다.
Swin Transformer은 작은 패치 사이즈로부터 계층적인 representation을 만들 수 있고 점진적으로 깊은 Transformer layer에서 이웃한 patch들과 merge를 할 수 있습니다.
Swin Transformer은 FPN과 U-Net같은 모델에서 영향력을 보여준다고합니다.
Swin Transformer의 핵심 설계 요소는 연속적인 self-attention사이에서 window 파티션들의 변화입니다.

Swin Transformer 아키텍쳐에서 self-atention을 계산하기 위한 shifted window 접근방식의 도식화입니다.
왼쪽 l번째 layer에서는 일반적인 window 분할 방식이 채택되었으며 각 window 내에서 self-attention이 계산됩니다.
다음 오른쪽의 l+1에서는 window 분할이 이동되어 새로운 window가 생성됩니다.
l계층의 이전 window들의 경계를 넘어서는 window들이 존재하며, 이들사이에 connection을 제공합니다.
shifted window는 앞의 layer의 window를 연결해주며 이들 사이의 연결을 통해 상당히 강화된 modeling power를 제공해줍니다.
shifted window 접근법은 all-MLP 아키텍쳐에서도 상당한 이점을 제공합니다.
Swin Transformer은 image classification, object detection, segmantic segmentation에서 높은 성능을 보였습니다.
Method

(a)Swin Transformer 아키텍쳐입니다.
(b)두개의 Suceesive Swin Transformer Block입니다.
W-MSA와 SW-MSA는 정규화와 shifted windowing의 도식화된 multi-head self attention module입니다.
이 저자들은 patch 크기를 4x4를 이용했다고합니다. 채널이 rgb로 3차원이니 이 패치들은 4x4x3입니다.
hierarchical representation을 생성하기 위해서 네트워크가 깊어짐에 따라서 token의 수는 patch mergeging layer에 대해서 줄어듭니다.
첫번째 patch merging layer은 2x2 이웃한 path 그룹의 feature을 연결하고 4C-dimensional에 연결된 특징에 선형계층을 적용합니다. 토큰수는 2x2 = 4 배로 줄어들며 출력차원은 2C로 설정됩니다.
stage를 거듭하면 거듭할수록 hierarchical representation을 생성할 수 있습니다.
MSA는 multi-head self-attention입니다. Swin Transformer은 표준 MSA모듈이 shifted window를 기반으로한 모듈로 대체되어 Transformer block을 구성합니다.
그다음 GLUE 비선형 함수를 사용하는 2층 MLP가 이어집니다. 각 MSA 모듈과 각 MLP사이에서는 LayerNorm 계층이 적용되고 각 모듈 후에는 잔차연결이 적용됩니다.

h x w patch의 이미지에 대한 계산복잡도 입니다.
여기서 전자는 patch 수 hw에 대해 이차적이며, 후자는 M이 고정되었을 때(기본적으로 7로 설정됨) 선형입니다.
global self-attention 계산은 일반적으로 큰 hw에 대해서는 부담스럽지만, window 기반 self-attention은 확장 가능합니다."
Figure 2에서 보여지는것처럼 첫번째 모듈은 왼쪽상단 픽셀에서 정규 window 분할 전략을 사용하고 8 x 8 feature map은 크기가 4x4인 2x2 window로 분할됩니다. 그다음 모듈은 이전 layer의 window 구성과 달리 정규 window 분할로부터 M/2, M/2 픽셀만큼 window를 이동하여 shift된 window 구성을 채택합니다.
식은 이렇게 구성된다고 합니다.

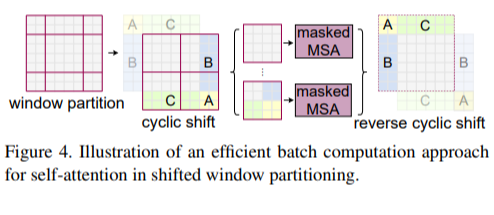
그림 4처럼, shift 후에 배치 window는 feature map에서 인접하지 않은 여러 하위 window로 구성될 수 있으므로, 마스킹 메커니즘이 사용되어 각 하위 window 내에서 self-attention 계산을 제한합니다. cyclic-shifting을 사용하면 배치 window의 수가 정규 window 분할의 수와 동일하게 유지되므로 효율적입니다.
Experiments

ImageNet-1k와 Imagenet-22K일때의 모델들 성능비교 표입니다.

COCO데이터셋으로의 모델들을 backbone으로 사용했을때 object detection 성능 비교표입니다.

semantic segmentation task에서 성능을 비교한 표입니다.

자세한 아키텍쳐 구성표입니다.(win sz = window size)

input size가 커질수록 Swin-B의 성능이 가장 좋습니다.

Optimizer을 비교한 표입니다.
'논문 > vision_transformer' 카테고리의 다른 글
| AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 논문정리 (0) | 2023.08.04 |
|---|---|
| big_transfer(BIT) pytorch 구현 (0) | 2023.08.02 |

댓글