Abstract
BERT는 모든계층에서 왼쪽 오른쪽 context를 모두 고려한 unlabeled text로부터 깊은 양방향의 representation을 pretrain하기위해서 디자인 되었습니다.
결과적으로 pre-trained된 BERT모델은 추가적인 출력계층만으로 sota model이 되었습니다.
이는 질문응답과 언어추론같은 다양한 task에 특정작업에 대한 구조변경없이도 가능합니다.
BERT
저자들은 Bert를 자세하게 소개합니다.
이 프레이뭐크에서는 pre-trainiing과 fine-tuning 두가지 step이 존재합니다.
pre-training동안 모델은 다른 pre-training task에서 라벨되지않은 데이터로 학습됩니다.
fine-tuning동안 BERT model은 pre-train된 파라미타로 초기화시키며 모든 파라미타는 fine-tuned된 downstream task로부터 label이 되어있는 데이터를 사용합니다.
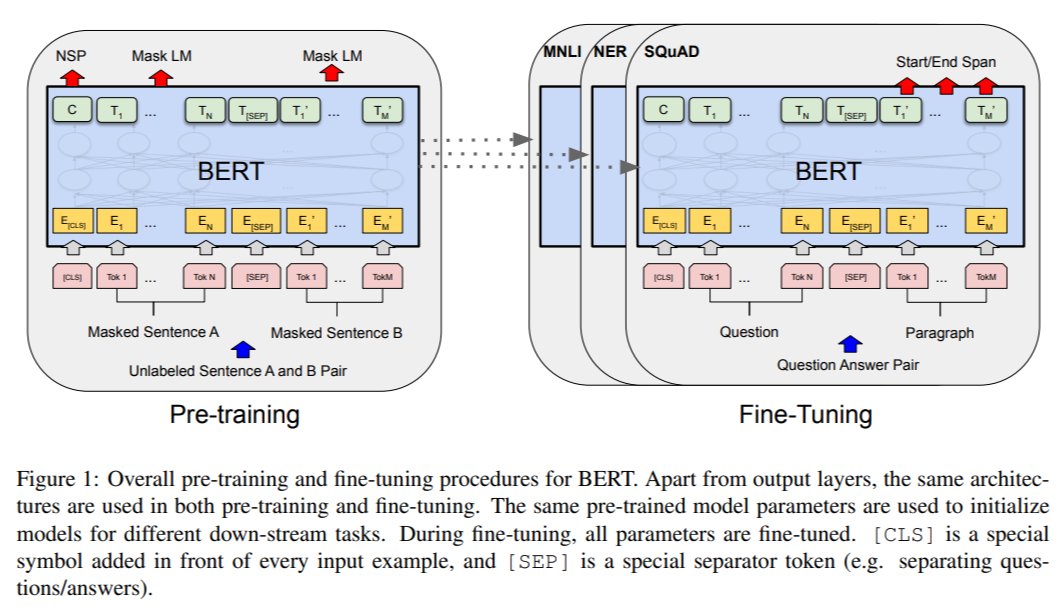
BERT 는 pre-trained 된 모델과 fine-tuned 된 모델 사이의 구조적 차이가 거의 없게 됩니다.
Model Architecture
BERT의 모델구조는 multi-layer 양방향 Transformer encoder를 베이스로 합니다.
이 연구에서 저자들은 레이어의 수를 L로 표시하고 hidden size를 H, self-attention head의 수를 A로 표시합니다.
Bert Transformer은 양방향의 self-attention을 사용하고 GPT-Transforme는 constrained self-attention을 사용합니다( 여기에서 모든 토큰은 context 왼쪽에서 들어갑니다).
Input/Output Representation
BERT모델은 down-stream task에서도 다룰 수 있으며 one token 시퀀스에서 single sentence와 sentence 한 쌍에서 input representation은 모호하지않게 represent를 할 수 있습니다.
저자들은 30000 token 단어들을가진 WordPiece embedding을 사용합니다.
모든 sequence에서 첫번째 token은 항상 special classification token ([CLS])입니다.
이 token에 상응하는 마지막 hidden state는 classification task에서 sequence 표현을 집계함으로써 사용됩니다.
저자들은 두가지 방법에서 sentence들을 구별짓습니다.
먼저 저자들은 special token([SEP])으로 그것들을 구별짓습니다.
두번째 저자들은 학습된 embedding을 모든토큰을 나타내기위해서 추가하고 그것은 sentence A와 setence B에 속해질 수 있습니다.
input representation=은 corresponding token, segment, position embedding으로 이루어져있습니다.

Task #1: Masked LM
깊은양방향 model을 믿는 이유는 left-to-right model보다 훨씬 강력하고 left-to-right와 right-to-left model의 얕은 concatenation보다도 더 강력하기 때문입니다.
깊은 양방향의 representation을 훈련하기위해서 저자들은 간단하게 input token의 확률을 random하게 mask했으며 이러한 masked된 토큰을 예측했습니다.
이 저자들은 이 과정을 masked LM(MLM)이라고 합니다.
이것은 우리에게 양방향 사전 훈련된 모델을 얻게 해주지만, 단점은 사전 훈련과 미세 조정 사이에 불일치를 만들냅니다. 그로인해 [MASK] token은 pre-training에만 사용되고, fine-tuning 과정에서는 사용되지 않습니다.
데이터를 훈련시킬때 랜덤적으로 15%의 token position을 선택하여 예측했습니다.
(1)80%의 경우에 i번째 토큰을 선택했을때 i번째 토큰을 [MASK]token으로 대체했습니다.
(2)10%의 경우에 i번째 토큰을 random token으로 바꿉니다.
(3)10%의 경우에 i번째 토큰을 바꾸지않습니다.
Task #2: Next Sentence Prediction (NSP)
question Answering(QA)와 Natural language Inference(NLI)와같은 중요한 downstream task는 two sentence들 사이에서 관계를 이해하는것을 기반으로 두는데 이것은 language modeling으로 잡는것은 불가능합니다.
문장 관계를 이해하는 모델을 훈련시키기 위해 저자들은 어떤 단일 언어 말뭉치에서도 쉽게 생성될 수 있는 이진화된 다음 문장 예측 작업을 위해 사전 훈련을 진행합니다.
구체적으로 pre-training example로 문장A와 B를 선택할때, 50퍼센트는 실제 A의 다음 문장인 B를(IsNext), 나머지 50퍼센트는 랜덤 문장 B를(NotNext) 고릅니다.
Figure 1에서 C는 다음 문장을 예측(NSP)하는데에 사용됩니다.
Fine-tuning BERT
Fine-tuning 과정은 비교적 간단한데, Transformer의 self-attention 메커니즘 덕분에 BERT는 많은 downstream task를 모델링 할 수 있다.

GLUE Test Result

layer수가 많을수록 성능도 증가하고있습니다.
Conclusion
언어 모델과의 전이 학습으로 인한 최근의 경험적 개선은 풍부하고 비지도 사전 훈련이 많은 언어 이해 시스템의 중요한 부분임을 보여줍니다. 특히, 이러한 결과는 심지어 자원이 적은 작업조차도 깊은 단방향 아키텍처로부터 이익을 얻을 수 있게 합니다. 우리의 주요 기여는 이러한 결과를 깊은 양방향 아키텍처로 더 일반화하고, 동일한 사전 훈련된 모델이 광범위한 NLP 작업을 성공적으로 처리할 수 있게 합니다.
'논문 > Natural Language Processing' 카테고리의 다른 글
| GPT1-Improving Language Understandingby Generative Pre-Training_논문정리 (0) | 2023.11.07 |
|---|

댓글