Abstract
현재 text detetion분야는 segmentation-based 와 regression-based 방법이 있습니다.
저자들은 segmentation과 regression을 혼합한 DETR-base모델을 사용합니다.
저자들의 주요한 분석은 우수한 decoder layer에서 우수한 segmentation 예측을 얻을수 있음을 나타냅니다.
이점을 고려해서 저자들은 segmentation branch를 초기 몇 개의 디코더 층에만 포함시키고, 이후 점진적인 회귀 개선을 사용하여 mask로인한 computation load를 최소화하며 성능 향상을 달성했습니다.
게다가 저자들은 Mask-informed Query Enhancement module을 제안합니다.
저자들은 segmentation 결과를 natural soft-ROI와 추출한 robust pixel 표현으로 가져옵니다. 그리고 이것은 쿼리를 더욱 개선하고 다양화시키는 것을 더욱 강화합니다.
이렇게 sota를 달성했습니다.
Intorudce
Regression-based model은 놀라운 장점을 제공하며 계산적으로 효율적이고 다양한 크기의 text에 적용가능하고 작고 큰 real-time에서의 text도 감지할 수 있습니다. 게다가 end-to-end learning 접근 pipeline은 기하학적 계산과 함께 전처리가 가능합니다.
그러나 이러한 방식은 segmentation-based 모델의 접근 방식과 비교해서 localization 정확도가 약간 낮습니다. 텍스트가 주변 배경과의 대비가 부족할 때도 어려움을 겪을 수 있으며, 이는 복잡한 환경에서 취약하게 만듭니다.
segmentation기반 모델들도 각각의 장점과 한계가 있습니다.픽셀 수준의위치 정밀도를 제공할 수 있으며, 다양한 글꼴 스타일, 크기 및 방향과 같은 텍스트 외관의 변화에 강건합니다. 그러나 binary mask에서 완전한 인스턴스를 추출하기 위해 복잡한 후처리가 필요하며, 이는 추가 알고리즘적 개입을 포함하여 GPU 병렬처리에 적합하지 않습니다.
저자들은 이 방법들을 결합한 object detection에서 인기있는 DETR모델을 통해 이 두표현을 통합할 수 있는 적절한 프레임워크를 제안합니다.
위에서 언급한 문제들을 해결하기 위해 저자들은 SR-Former이라는 DETR기반의 모델을 제안합니다. 이 모델은 분리된 decoder 청크들을 가지고 있으며 segmentation 청크들은 모대ㅔㄹ이 더 강력한 픽셀 표현을 학습하도록 돕고, 텍스트와 비텍스트 영역을 더 잘 구부낳며, 보다 정밀한 회귀를 위한 위치 정보를 제공합니다.
반면 regreaaion chunk는 query를 통해 높은 수준의 특징을 잡도록 유돟며 최소한의 후처리로 localization 결과를 더욱 세밀하게 개선합니다. 저자들은 최종 예측 결과로 segmentation mask를 직접 사용하는 대신, 정확한 예측과 복잡한 후처리 절차를 필요로 하는 것을 회피하기 위해 Mas-informed Query Enhancement 모듈을 도입했습니다. 이 모듈은 mask를 ROI(관심 영역)의 고유한 지표로 활용하여 localization영역에서 독특한 특징을 추출합니다. 쿼리를 더욱 개선하고 다양화시키는 것을 더욱 강화합니다.
Methodology
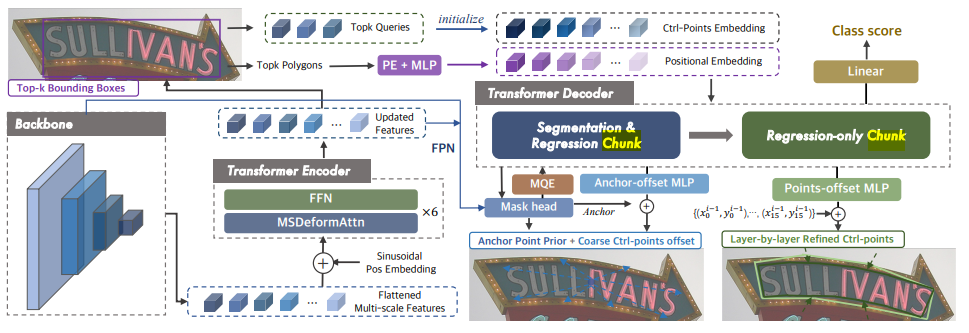
Model Architecture
Fig1은 SRFormer 아키텍쳐입니다.
저자들은 Resnet50을 backbone으로 사용합니다.
flatten된 피쳐들을 transformer encoder에 넣어준다. 저자들은 backbone과 업데이트된 feature들을 feature pyramid network 모듈에 넣어줍니다.
fuse된 피쳐들은 decoding 단계와 mask 예측 head 양쪽으로 전달되며 프레임워크 내에서 기본 참조 역할을 합니다.
고해상도의 backbone 피쳐들은 원래의 DETR segmentation head에서 관측된 bottleneck 정보를 다룹니다. 그리고 저자들은 two-stage 접근방식을 사용합니다.
공유된 그룹의 decoder embedding이 인코더 출력으로 초기화되고, cross-attention 매커니즘을 통해 더 풍부한 특성을 수집하기 위해 decoder에 공급됩니다. 우리는 초기 몇 개의 층을 세그멘테이션 및 회귀층별로 세밀한 조정을 통해 더 정밀한 다각형 제어 점을 얻습니다. 마스크, 좌표, 및 클래스 점수 예측을 위한 여러 헤드가 병렬방식으로 채택됩니다.
Query Formulation
이전 성공에서 유래된 바에 따라, 더 나은 성능과 빠른 훈련 수렴을 위해 디코더 쿼리를 인코더 출력으로 초기화합니다.
저자들은 제안 수 K의 학습 가능한 매개변수 수를 설정하는 대신, 점별 특성과 일반적인 제어 포인트 상관 관계를 캡처하기 위해 학습 가능한 임베딩의 16개 그룹만을 설정합니다.
인스턴스 수준과 제어 포인트 수준의 쿼리를 결합하여 계층적 표현을 형성함으로써, 저자들은 인스턴스 수준의 주의를 통해 유사한 예측을 걸러내고, 포인트 수준의 주의를 통해 global point to point 상대적 관계를 모델링할 수 있습니다.
또한 인코더에서 bounding box 출력을 더 잘 활용하기 위해, 저자들은 제안된 방법(Ye et al. 2023a)에 따라 상자의 긴 변을 따라 시계 방향으로 균일하게 16개의 등간점을 샘플링합니다. 이 샘플된 점들은 초기 다각형 예측으로 사용됩니다.

Segmentation & Regression Chunk
Fig. 1에서 시연된 대로, 디코더 초기 레이어에서만 텍스트 인스턴스 세그멘테이션을 수행합니다.
실험 결과에 따르면, 인스턴스 세그멘테이션 마스크는 초기 몇 개의 레이어에서 유리한 결과를 보이지만, 깊은 디코더 레이어에서도 개선된 쿼리 표현을 사용해도 층별로 세밀하게 개선하기 어렵다고 합니다. 이 구현을 통해, 디코더의 계산 비용을 줄이면서도 성능 저하를 최소화할 수 있습니다. 마스크 예측을 수행하기 위해, 저자들은 백본(backbone)과 인코더 피처에서 융합된 픽셀 임베딩 맵을 구축합니다. 디코더의 쿼리는 계층적으로 구성되어 있기 때문에, 텍스트 인스턴스 수준의 예측을 위해 점 수준 쿼리를 집계하는 것이 중요해집니다.
mask head와 비슷한 사진은 fig2에 있습니다.
먼저, 기본 설정에서 큰 커널 크기 (k = 9)의 1D Convolution을 사용하여 inter-point 기하학적 관계를 포착합니다. 이 후에는 1 × 1 Convolution 레이어를 사용하여 point-level 집계 가중치를 학습합니다. 그런 다음, 제어 포인트 차원을 따라 쿼리의 weighted sum을 채택하여 마스크 임베딩을 적응적으로 구성합니다. 마지막으로, 각 마스크 임베딩 qm을 픽셀 임베딩 맵 F의 1/8과 점곱(dot product)하여 인스턴스 마스크 m을 얻습니다.
Mask as regression prior
segmentation mask와 polygon control point의 차이를 연결하기 위해서 저자들은 같은 해상도의 anchor grid map segmentation mask로써 사용했습니다. 텍스트와 비텍스트 영역과 관련된 응답 값을 다루는 데 있어서, 더 낮은 응답 값을 가지지만 더 큰 픽셀 범위를 포함하는 비텍스트 영역의 잠재적인 영향을 최종 앵커 결과에 미치지 않도록 완화할 필요가 있습니다. 대부분의 텍스트 인스턴스는 규칙적인 볼록 기하학적 형태를 가지므로, 그 무게 중심이 기하학적 중심과 일치하게 되어 회귀(regression) 목적에 적합한 기준점이 됩니다.
Mask-informed Query Enhancement
이전의 연구는 decoder cross-attentioin 매커니즘을 드러냅니다. 그리고 이것은 soft ROI -Polling처럼 사용됩니다. ROI는 명시적으로 positional embedding에서 encode되었습니다. 저자들은 isntance mask를 일종의 soft ROI로 사용하여 인코더 특징에서 인스턴스 수준의 특징을 추출하고 이 특징을 원래의 query representation에 직접 추가하는 방법을 휴리스틱하게 채택합니다. 그리고 이것은 cross-attention을 사용해서 point-level에서 피쳐를 추출합니다.
End-to-End Optimization
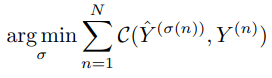
matching 과정에서 주요한 목표는 예측 값과 실제 값 사이의 매칭 cost를 최소화하는것입니다. 저자들은 이분 매칭 문제를 해결하기 위해 헝가리안 매칭을 사용합니다.
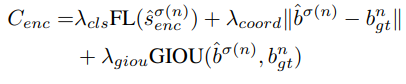
cost function 설계에 있어서 인코더 출력의 상황 내에서 경계 상자에 대한 GIOU 손실과 L1 손실, 그리고 분류 점수에 대한 변형된 focal loss를 사용합니다.
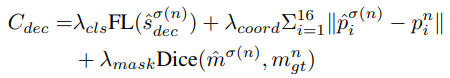
디코더도 인코더와 유사한 함수를 사용하는데 Dice 손실(Dice loss)은 분할 및 회귀 레이어에서만 사용되며, 이 비용 함수에 독점적으로 통합됩니다.
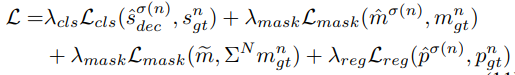
Loss function입니다.
Experiment
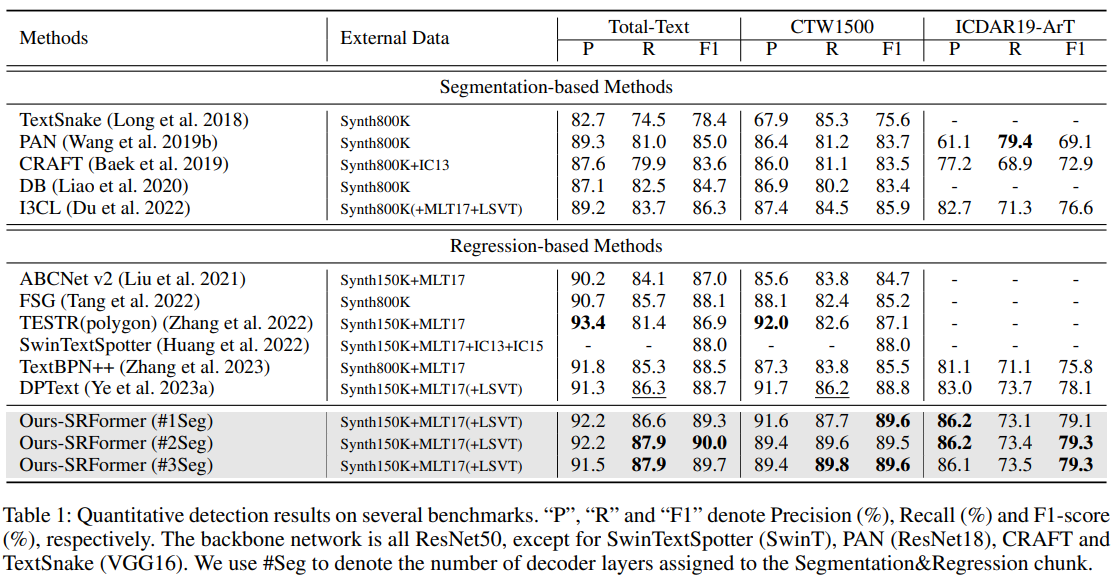
SRFormer의 성능이 좋음을 나타냅니다.
'논문 > text detection' 카테고리의 다른 글
| TextFuseNet: Scene Text Detection with Richer Fused Features (1) | 2024.07.01 |
|---|

댓글